This post is about create a SQLite3 schema to store the Spotify data set in at least 3rd normal form (3NF), populate the tables and then using an example SQL query to find the names of all playlists that contain instrumentals.
The detailed source codes to is included in this notebook.
You can also check the Spotify SQL folder in my Github Repo ZhiQiu976/source-codes-tech-posts to access the normalized Spotify database.
Database Normalization
Database normalization is performed for two main reasons - reduce redundancy and prevent inconsistencies on insert/update/delete.
Note: A fully normalized database is in domain-key normal form (DK/NF) if every constraint is a logical consequence of the definition of the candidate key and domains. However, most practical normalization procedures go through a series of steps known as first, second and third normal forms, and ignore potential modification anomalies that may remain.
Outcome:
- Every table should not have any
- duplication
- dependencies that are not key or domain constraints
First Normal Form (1NF)
- Table has a primary key (unique, non-null column that identifies each row)**
- No repeating groups of columns
- Each cell contains a single value
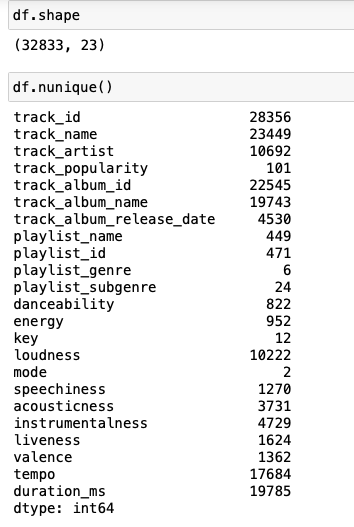
Clearly there is no unique primary key in the original dataframe and this is perhaps because the original dataframe is a denormalized version and not in a SQLite3 schema (so no concept of primary key in this original dataset). Therefore, we skip requirement 1 at this stage.
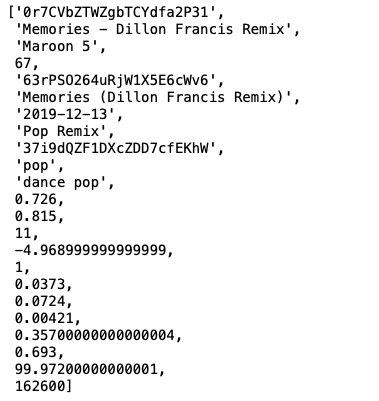
For requirement 2 and 3, we can see from the original data description) and the above example record that there is no repeating groups o columns and each cell contains a single value.
Second Normal Form (2NF)
- All columns in each row depend fully on candidate keys
- Identify candidate Primary Key for each row
- If there is a composite PK, see if other columns have partial dependencies
To achieve 2NF, we would breake the original dataset into three sub-datasets:
df_song = df[['track_id', 'track_name', 'track_artist', 'track_popularity',
'danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness',
'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo',
'duration_ms']]
df_album = df[['track_album_id', 'track_album_name', 'track_album_release_date']]
df_playlist = df[['playlist_id', 'playlist_name', 'playlist_genre', 'playlist_subgenre']]
Third Normal Form (3NF)
- No transitive dependencies between non-candidate columns
In order to achieve 3NF, we further split and organize the above three datasets into 6 datafrmes:
- df_song: track_id, track_name, track_artist, track_popularity and the other song characteristics
- df_album: track_album_id, track_album_name track_album_release_date
- df_playlist_new: playlist_id, playlist_name, playlist_genre
- df_playlist_subgenre: playlist_genre, playlist_subgenre
- df_song_album: track_id and track_album_id
- df_song_playlist: track_id and playlist_id
df_song = df_song.drop_duplicates(subset=['track_id'])
df_album = df_album.drop_duplicates(subset=['track_album_id'])
df_playlist = df_playlist.drop_duplicates(subset=['playlist_id'])
df_playlist_new = df_playlist[['playlist_id', 'playlist_name', 'playlist_genre']]
df_playlist_subgenre = df_playlist[['playlist_genre', 'playlist_subgenre']].drop_duplicates(
subset=['playlist_genre'])
df_song_album = df[['track_id', 'track_album_id']].drop_duplicates(subset=['track_id'])
df_song_playlist = df[['track_id', 'playlist_id']].drop_duplicates(subset=['track_id'])
SQLite3 schema
Now that we have done the normalizetion part, we could directly construct a SQL database for the above dataframes:
import sqlite3
# Create database
con = sqlite3.connect('spotify.db')
# Create tables in the database
df_song.to_sql(name='song', con=con, index = False)
df_song_album.to_sql(name='song_album', con=con, index = False)
df_album.to_sql(name='album', con=con, index = False)
df_song_playlist.to_sql(name='song_playlist', con=con, index = False)
df_playlist_new.to_sql(name='playlist_new', con=con, index = False)
df_playlist_subgenre.to_sql(name='playlist_subgenre', con=con, index = False)
The details of this schema are shown as below, the sql queries used to construct this database could be found in the last column:

Example SQL query
Now we would use a SQL query to find the names of all playlists that contain instrumentals:
%%sql
SELECT COUNT(*) AS num_song, playlist_name
FROM song
INNER JOIN song_playlist
ON song_playlist.track_id = song.track_id
INNER JOIN playlist_new
ON playlist_new.playlist_id = song_playlist.playlist_id
WHERE instrumentalness > 0.5
GROUP BY playlist_name
ORDER BY num_song DESC
Here are 10 example playlists that contain instrumentals, ordered by the number of songs in each playlist:
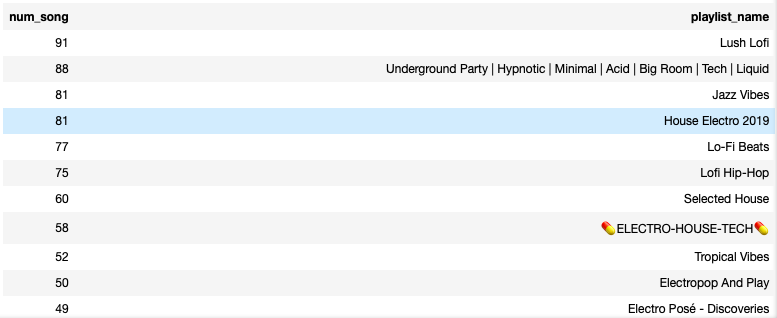
The above is just a simple example query and we can certainly use many other queries to explore and take further use of this Spotify database freely via SQL. ✨