This post is about training a deep learning model to classify beetles, cockroaches and dragonflies using these raw images. Note: Images are collected from Insect Images.
You may also access the zip file of images and the analysis notebook in the Deep Learining folder of my GitHub source codes repo.
Dara Preparaton
Firstly, the raw images need to be read in (with check of empty and duplication) and transformed for image processing:
def image_read_in(directory, check_directory = None):
'''
Read in original images with check for duplication and empty. Transform into array.
'''
img_ = []
for file in os.listdir(directory):
# check for duplicate
if check_directory is not None and file in os.listdir(check_directory):
continue
img = cv2.imread(directory + '/' + file)
if img is not None:
img = cv2.resize(img, dsize=(84, 84), interpolation=cv2.INTER_CUBIC)
img_.append(img)
return img_
Then I constructed training and testing sets for each category separately:
def save_by_type(cat, code, train_path, test_path):
'''
Read in and save images by type. Label each type by a numerical code.
'''
directory1 = train_path + cat
directory2 = test_path + cat
# training
X_cat_train = image_read_in(directory1, directory2)
y_cat_train = np.repeat(code, len(X_cat_train))
# testing
X_cat_test = image_read_in(directory2)
y_cat_test = np.repeat(code, len(X_cat_test))
return X_cat_train, X_cat_test, y_cat_train, y_cat_test
The shape can size of each category in training and testing data sets are as following:

Then we combine all three categories (beetles, cockroaches and dragonflies) and our final training data set contains 839 colored images of shape (84, 84, 3) and testing data set contains 180 colored images of shape (84, 84, 3).
Next, we will prepare our dataset for use in Neural Network trainings cia PyTorch with a selected batch size of 32 (In general, batch size of 32 is a good starting point, and you can also try with 64, 128, and 256.):
batch_size = 32
# pytorch preprocessing
X_train_ = torch.Tensor(np.array(X_train) / 255) # the pixels falling in the range [0, 255], Normalize value to [0, 1]
X_test_ = torch.Tensor(np.array(X_test) / 255)
y_train_ = torch.Tensor(y_train).long()
y_test_ = torch.Tensor(y_test).long()
train_set = torch.utils.data.TensorDataset(X_train_, y_train_)
test_set = torch.utils.data.TensorDataset(X_test_, y_test_)
train_loader = torch.utils.data.DataLoader(dataset=train_set, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_set, batch_size=batch_size, shuffle=False)
CNN - LeNet-5
Now we will introduce the CNN architecture we are going to use - Lenet-5:
LeNet is a classic CNN architecture for MNIST dataset proposed in 1990’s by LeCun et al. in their 1998 paper, Gradient-Based Learning Applied to Document Recognition. As the name of the paper suggests, the authors’ implementation of LeNet was used primarily for OCR and character recognition in documents (like the MNIST dataset).
The LeNet architecture is straightforward and small, (in terms of memory footprint), making it perfect for teaching the basics of CNNs — it can even run on the CPU (if your system does not have a suitable GPU), making it a great “first CNN”. However, when using GPU support, you can enjoy extremely fast training times (in the order of 3-10 seconds per epoch, depending on your GPU).
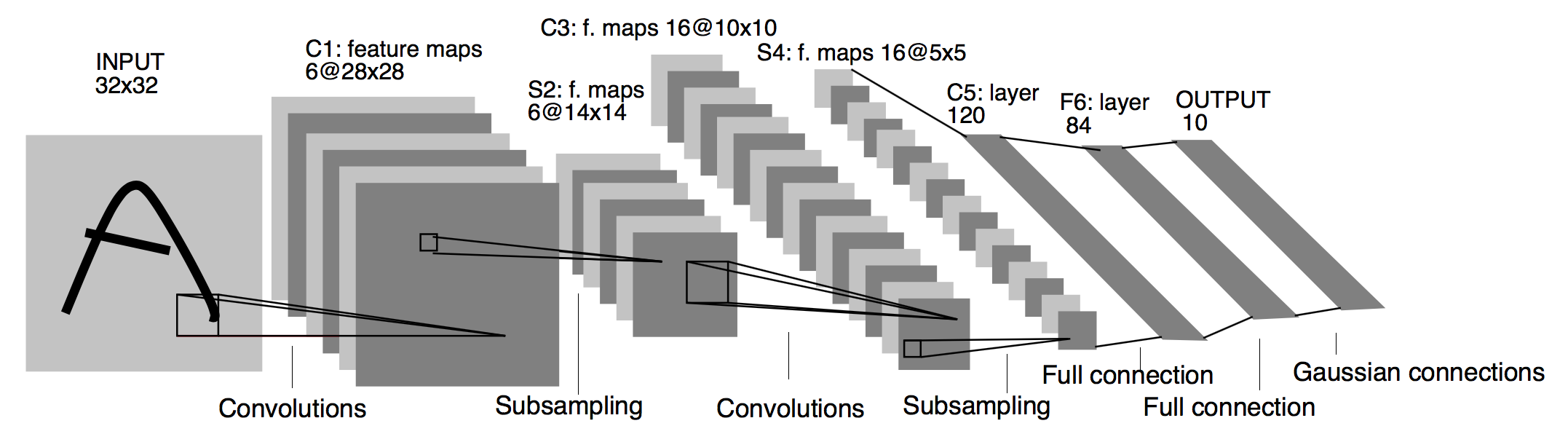
CNN in LeNet-5 for our Data
In order to apply this framework to our data, we need to change some parameters:
class LeNet5(nn.Module):
def __init__(self, in_channels, out_channels):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=16, kernel_size=3, stride=2, padding=1, bias=True) # in=3
self.conv2 = nn.Conv2d(in_channels=16, out_channels=64, kernel_size=3, stride=1, padding=0, bias=True)
self.fc1 = nn.Linear(in_features=64 * 9 * 9, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=84) # attempted kernel 32, 64, 128, 256
self.fc3 = nn.Linear(in_features=84, out_features=out_channels) # out=3
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Note that for our colored images, in_channels is 3 and out_channels is also 3. You can use other kernel size, kernel number, stride and padding in layers as long as it fits the overall CNN structure. As for the internel kernel size, I attempted 32, 64, 128 and 256 and found 256 works best for this data set.
Next is the regular training and testing (train, test and optimizer functions could be found in my source codes notebook) with selected learning rate, epoch number and optimizer (I used Cross Entropy Loss as criterion):
# using seed to make this analysis reproducible
seed = 1
device = 'cuda'
optimizer_name = 'SGD'
num_epochs = 50
lr = 0.005
device = torch.device(device)
torch.manual_seed(1)
torch.cuda.manual_seed(1)
in_channels = 3
out_channels = 3
model = LeNet5(in_channels, out_channels).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = make_optimizer(optimizer_name, model, lr=lr, momentum=0, weight_decay=0)
train_acc = []
test_acc = []
for epoch in range(1, num_epochs + 1):
a = train(model, device, train_loader, criterion, optimizer, epoch)
b = test(model, device, test_loader, criterion, epoch)
train_acc.append(a)
test_acc.append(b)
if epoch == 1 or b > last: # save the best model
torch.save(model.state_dict(), 'lenet.pth')
last = b
#scheduler.step()
print('Optimizer Learning rate: {0:.4f}'.format(optimizer.param_groups[0]['lr']))
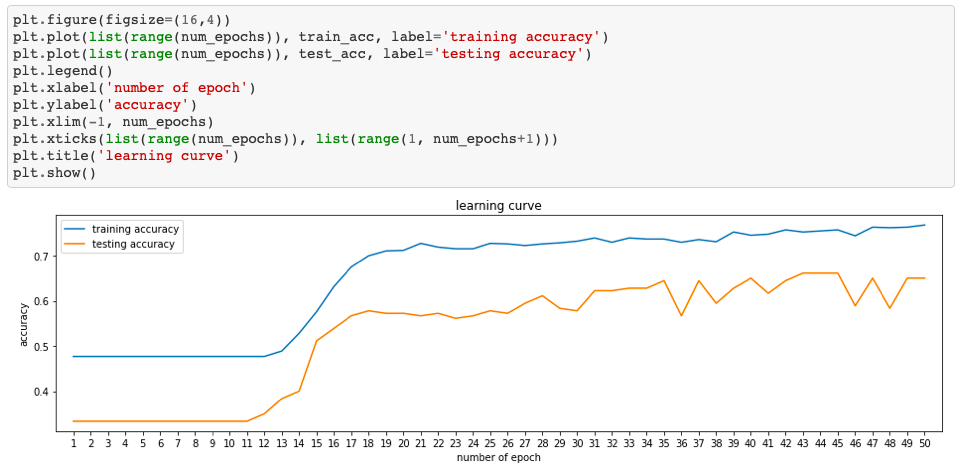
As you can see in the above figure, with SGD optimizer, I tuned the model with 0.005 learning rate and 50 epochs and achieved about 65% accuracy.
The we will attempt Adam optimizer:
seed = 1
device = 'cuda'
optimizer_name = 'Adam'
num_epochs = 60
lr = 0.0005
device = torch.device(device)
torch.manual_seed(1)
torch.cuda.manual_seed(1)
in_channels = 3
out_channels = 3
model = LeNet5(in_channels, out_channels).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = make_optimizer(optimizer_name, model, lr=lr, momentum=0, weight_decay=0)
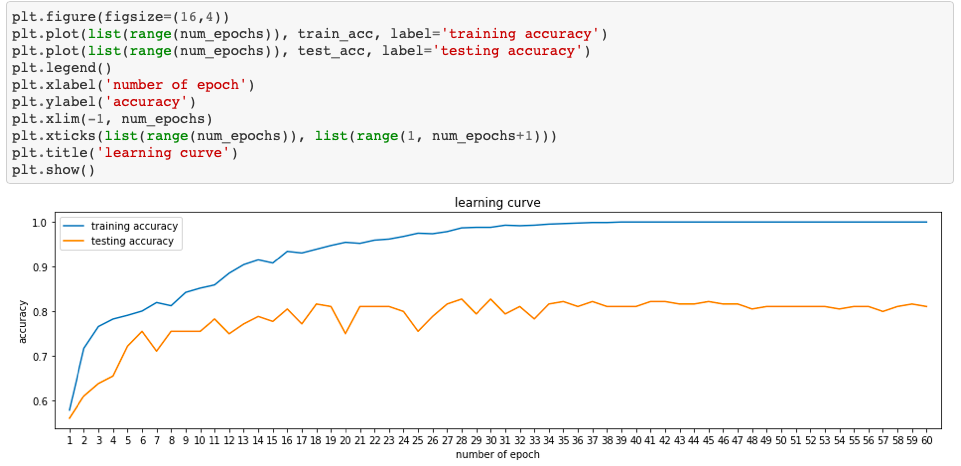
With 0.0005 learning rate and 60 epochs this CNN model achieved pretty good accuracy of about 80%.
Conclusion
CNN model and LeNet architecture is not only useful for character recognition but also effective with image processing. With such a small number of data, this architecture could still perform quite well in classification! ✨